














|
Электронная версия. Полная опубликована в "Горном информационно-аналитическом бюллетене", выпуск 5, 1999 год.
К ВОПРОСУ О ПОЛУЧЕНИИ НЕСМЕЩЕННЫХ ОЦЕНОК ПРИ ГЕОСТАТИСТИЧЕСКОМ МОДЕЛИРОВАНИИ С ИСПОЛЬЗОВАНИЕМ НЕЛИНЕЙНЫХ НОРМАЛИЗУЮЩИХ ПРЕОБРАЗОВАНИЙ В.А.Мальцев (ВНИИгеосистем)
РЕФЕРАТ В статье предлагается новый подход к компенсации смещения оценок, возникающего при моделировании с применением логнормальных распределений, гарантирующий отсутствие систематических ошибок даже в случае существенного расхождения реального распределения с теоретическим. Подход легко обобщается на широкий подкласс распределений Кептейна, делая их реально применимыми в задачах моделирования. Проводится сравнение с распространенным в настоящее время мультигауссовским подходом, также решающим эти проблемы, но дающим результаты, “визуально менее приемлемые” для предметного специалиста. ABSTRACT On receiving non-biased results when modelling through non-linear normalizing data conversions. The paper suggests some new approach to the problem of the estimation biases elimination when a log normal modelling is used. This approach guarantees non-biased results even when the real distribution is far enough from the theoretical. A wide sub-class of Captain's distribution functions may be also used in practical modelling tasks through this approach. The new approach is compared to the MG approach, solving the same tasks, but returning results, that are “less visually acceptable” for a geologist. Введение В задачах интерполяции, оценивания и имитационного моделирования, связанных с пространственным распределением признаков в рудных месторождениях, часто встает необходимость учета левой асимметрии распределения исходных данных. Такой учет позволяет существенно более адекватно моделировать пространственные распределения исследуемых признаков [Reply, 1981]. Имея в виду, что статистические и геостатистические процедуры имеют обозримую математику исключительно для случая нормального распределения, наиболее распространенный подход состоит в замене исходного признака Причина этого достаточно проста - любое нелинейное преобразование над
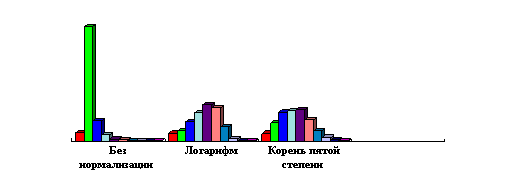
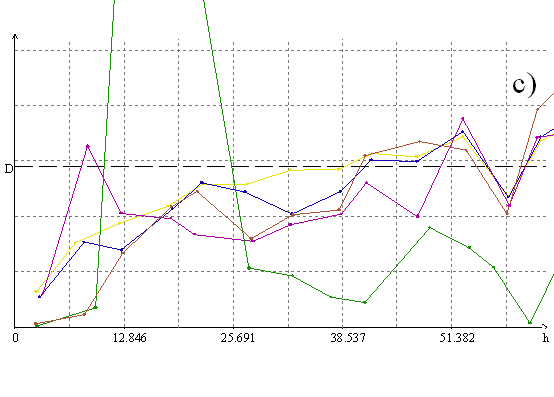
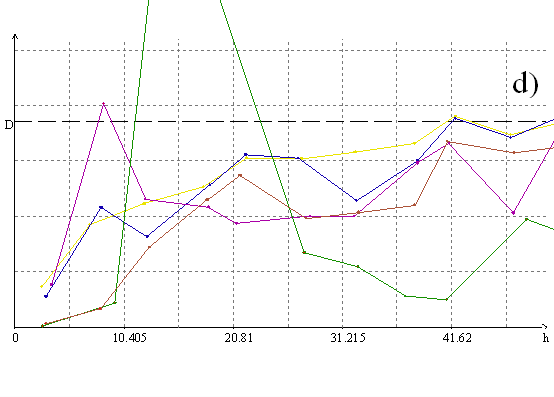
Однако механизм формирования распределений геологических признаков совсем не обязательно приводит именно к логнормальному распределению - могут возникать самые разнообразные распределения Кептейна. Более того, логнормальное распределение “в чистом виде” возникает исключительно редко. Так, в [Howart & Earle, 1979] рассматривается большая статистика моделирования геохимических ореолов, и ни в одном из случаев логарифмическое преобразование не оказалось предпочтительным - только степенные. Из общих соображений это понятно. Обратимся к физическим механизмам формирования распределений. Как известно, нормальное распределение есть результат взаимодействия стремящегося к бесконечности числа равномерно или нормально распределенных факторов, участвующих аддитивно. Логнормальное - аналогично, но при мультипликативном участии факторов. Посмотрим теперь с точки зрения физики механизм формирования оруденения, к примеру, гидротермального. Оруденение возникает при разрушении некоторой системы термодинамического равновесия, “висящей” на вполне конечном и небольшом числе факторов (обычно в пределах десяти). Очевидно, что мультипликативным характером взаимодействия в сильно неравновесном процессе будут обладать только эти факторы, которых для формирования логнормального распределения просто мало. Если все факторы при этом распределены равномерно - возникает распределение, приводящееся к нормальному корнем степени, равной числу факторов, если нет - легко не нормализующееся, но хотя бы приводящееся указанным преобразованием к симметричному. Для иллюстрации можно обратиться к рис. 1., на котором хорошо видно, что оптимальной нормализующей трансформацией в данном случае является корень пятой степени.
Суть проблемы Понятно, что в условиях отсутствия стандартных компенсаций смещения для случаев, отличных от логнормального, исследователь, как правило, стоит перед дилеммой - не учитывать асимметрию нельзя, распределение данных не вполне согласуется с логнормальным законом, хотя весьма близко к нему, а истинный его вид установить все равно невозможно. Логнормальное распределение здесь выступает в качестве "достаточно хорошего и удобного первого приближения", а следующее приближение обычно и не ищется. Использовавшийся до сравнительно недавнего времени прямой метод логарифмирования и последующего возврата логарифмических оценок с компенсацией смещения сейчас повсеместно кроме экс-СССР выведен из употребления, так как чувствительность его к нарушениям вида распределения исключительно высока [Journel, 1980; Deutch & Journel, 1992]. Для иллюстрации выкладок, приводимых в данной статье, рассмотрим два реальных массива: фрагмент Арсеньевского оловорудного месторождения, двумерные данные, метропроцент, эксплуатационная разведка, бороздовое опробование, 385 проб, среднее значение 2.48, и фрагмент Северного золоторудного месторождения Кураннахского поля, трехмерные данные, детальная разведка скважинами, 6985 проб, содержание, среднее значение 1.428. Получающееся смещение оценок приведено в таблице 1. При этом Арсеньевское обрабатывалось линейным двумерным кригингом, Кураннах - универсальным трехмерным с моделью квадратичного тренда вдоль вертикальной оси. Компенсация вводилась с учетом нестационарности, то есть по данным локальной эллиптической окрестности, число проб в которой ограничивалось снизу 10-ю. Все расчеты проводились средствами программы Geostatistical Software Tool [Мальцев, 1991, 1993а, 1993б] в версии 4.01, расширенной экспериментальными средствами.
После ухода “классической геостатистики” от логнормального моделирования потребовался какой-либо другой подход к проблеме, и данную “нишу” занял мультигауссовский подход (MG-approach) [Verly, 1983], впервые появившийся в тиражируемой реализации в пакете Geostatistical Toolbox (Стэнфордский Университет) в 1992-м году, с вариантом, независимо разработанным в России автором и включенном также в 1992-м в пакет Geostatistical Software Tool 3.0. Мультигауссовский подход состоит в вычислении весовых функций кригинга по данным, подвергшимся нормализующему преобразованию, но приложении этих функций к нетрансформированным данным. Математически этот подход, разумеется, далек от корректности, но практически дает вполне хорошие результаты в большинстве случаев. При этом проблема смещения оценок просто не возникает, а трансформации можно использовать не только логарифмические, но и любые, допустимые для распределений Кептейна.
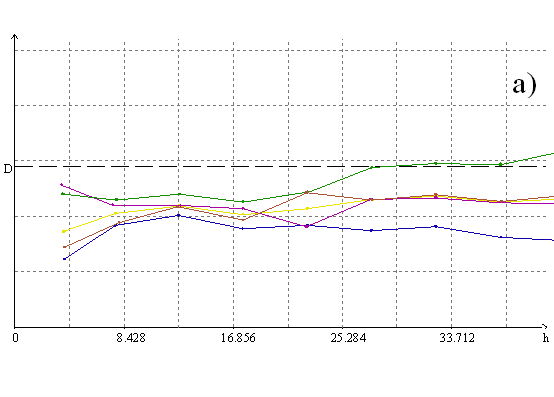
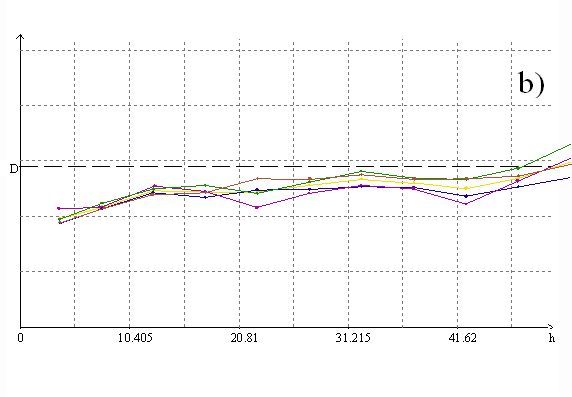
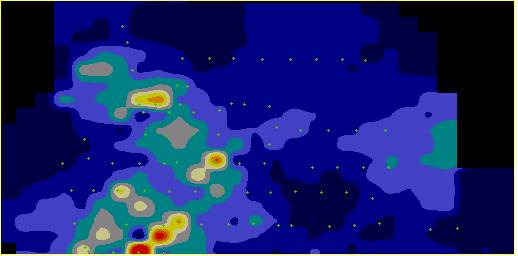
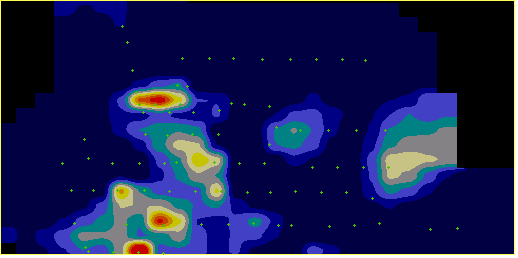
Хорошее статистическое качество мультигауссовского кригинга можно видеть хотя бы по данным перекрестного прогноза (статистика “накрываемости” и устойчивости прогнозных оценок на точки опробования, полученные без их участия в расчете). Для наших двух массивов эти результаты приведены в таблице 1, а используемые вариограммы - на рис. 2. Однако мультигауссовский подход имеет один существенный недостаток. Понятно, что для одних и тех же цифровых данных можно составить более одной статистически хорошей пространственной модели, и разумный критерий выбора здесь ровно один - отрисовав результаты моделирования в виде карт, проверить, будет ли их рисовка отвечать видению объекта геологом, знающим этот объект. Так вот по этому критерию мультигауссовский кригинг дает существенно менее убедительные карты, чем линейный кригинг с трансформацией данных, что можно видеть на фрагментах карт, приведенных на рис. 3.
Видится, что в идее вернуться к рассмотрению кригинга с трансформацией данных есть определенный смысл, разумеется, если удастся решить проблему компенсации смещения при возврате оценок не менее универсально и устойчиво, чем в мультигауссовском подходе. Заметим, что проблема рисовки карт из рассмотрения выпадает - как убедительно показано в [Journel, 1980; Howart & Earle, 1979], а также многократные эксперименты автора, рисовка карт с трансформированными данными более устраивает геологов, а различные подходы к компенсации смещения меняют уровни значений, но не меняют рисовку. Логический анализ ситуации Итак, начнем с логнормального распределения и “стандартной” компенсации смещения экспонентой полудисперсии логарифмов. Применение упомянутого компенсирующего множителя основано на ряде элементарных свойств логнормального распределения: Пусть Тогда То есть, применяя логарифмирование, мы переходим от средних оценок к медианным, а применяя компенсирующий множитель, возвращаемся обратно самым простым путем, уже не меняя пространственного распределения моделируемого признака (например, рисовки карты), а только масштабируя величины единым множителем. Все это абсолютно верно при действительно логнормальном распределении, но что же получается при применении логнормальной модели в качестве первого приближения? Два вышеприведенных равенства выполнены весьма приблизительно, причем второе обычно выполняется хуже первого. Так как дисперсия, как момент второго порядка, оценивается по выборочным данным гораздо менее устойчиво, чем среднее (момент первого порядка), возврат через множитель, вычисленный как функция от выборочной оценки дисперсии логарифмов, не может быть устойчивым при отклонениях распределения от логнормального. Имеется прямой резон повысить устойчивость заменой компенсирующего множителя, рассчитанного как Проведенные эксперименты показали, что при такой замене во всех изученных случаях величина смещения значимо уменьшается, становясь практически ненаблюдаемой. Вместе с тем предложенная выше замена компенсирующего множителя, хоть и уменьшает величину смещения, отнюдь не гарантирует его отсутствия. Из двух приведенных равенств, хоть первое и более устойчиво, но тоже выполняется приблизительно, то есть в реальности медиана логарифмов не совпадает со средним логарифмом. Продолжая развивать идею, перенесем и его "на второй план", заменив компенсирующий множитель непосредственно на Теперь посмотрим, что получилось. В случае реально логнормального распределения мы не изменили ничего, а в случае наличия возмущений гарантировали несмещенность оценок, переведя тем самым все ошибки, возникшие в результате не совсем адекватно описанного распределения, только в область пространственного перераспределения оценок. Что, скажем, для задач подсчета запасов принципиально важно, так как в них мы имеем право из тех или иных соображений модифицировать пространственные распределения подсчетных параметров, но не имеем права лишаться при этом гарантированной несмещенности оценки суммы запасов, а предложенный подход именно это и гарантирует, оставляя рисовку карты (как следствие выбранной логнормальной модели) "на совести" исследователя, выбравшего эту модель [Мальцев, 1993]. Отметим, впрочем, явно, что при предлагаемом подходе мы не добавляем дополнительных ошибок в рисовку, оставляя ее точно такой же, как и при обычном. Меняется только константный компенсирующий множитель, единый на всю моделируемую область. Подтвердить экспериментом выводы предыдущего абзаца невозможно. Любая проверка несмещенности оценок сводится в конце концов к проверке несмещенности относительно арифметического среднего экспериментальных данных, то есть того параметра, на который и происходит нормирование. Здесь может возникнуть впечатление, что предлагаемый метод является просто подгонкой результата, но еще раз отметим, что это не так. Подгонкой являлось бы нормирование на отношение среднего к средней полученной оценке, чего не происходит. Все нормирование выполняется до моделирования, а не после, а кроме того - предлагаемая технология является просто записью идеи со "стандартным" компенсирующим множителем, в которой акцент перенесен с математической красоты на устойчивость выборочных оценок. Добавим, что выборочные оценки, по которым рассчитывается компенсирующий множитель, в случае отсутствия общего тренда можно брать по полной выборке, а в случае наличия - по окрестности, задействованной в кригинге. Данные в таблице 1 получены с использованием оценок, рассчитанных по окрестности. Случай распределений, отличных от логнормального Рассмотрим, не будет ли полезен предложенный подход (назовем его подходом с адаптивной компенсацией) не только в случае логнормального моделирования, но и в случае моделирования посредством других распределений Кептейна. В широкой практике никакие другие распределения Кептейна обычно не применяются, так как для применения каждого из них нужно аналитически выразить через параметры закона С медианой все очевидно. Так как функция С математическим ожиданием несколько сложнее. В простом случае (функция
Понятно, что это не есть тривиальная задача, и она должна индивидуально выполняться для каждой из потенциально применимых функций Вместе с тем отметим, что так как математическое ожидание трансформированных данных совпадает с трансформированной медианой исходных, а компенсация смещения происходит единым множителем, все соображения, высказанные для логнормального распределения, остаются в силе. То есть, предложенный подход годится и для всех распределений Кептейна с взаимно однозначной функцией Некоторые предметные соображения позволяют даже слегка расширить класс допустимых функций Рассмотрим также вопрос несовпадения реального распределения с модельным. Здесь имеется одно очень простое соображение. Разумеется, если мы подобрали трансформацию так, чтобы элиминировать асимметрию, а по эксцессу распределение трансформированных данных сильно отличается от нормального, качество результата может оказаться и плохим. Но в этом случае простейшая из проверок перекрестным прогнозом (по коэффициенту корреляции факт/прогноз) показывает применимость модели весьма надежно. Данные по моделированию наших двух массивов с применением адаптивной компенсации и степенными трансформациями также содержатся в таблице 1.
Границы применимости подхода Нельзя не рассмотреть границ применимости предлагаемого подхода, явно описав класс моделирующих процедур, при которых несмещенность гарантируется. Как уже отмечалось во введении, большинство процедур оценивания точки или блока в пространстве в итоге сводится к весовой функции от значений в точках наблюдения (пробах) в некоторой окрестности оцениваемой точки или блока. Разница заключается в том, какой вид весовой функции используется, как выбираются весовые коэффициенты, и как обеспечивается "внутренняя несмещенность" весовых оценок (относительно среднего логарифма). Для получения точечных оценок автор использовал так называемый "обычный" кригинг (линейный с условием несмещенности), при котором весовая функция - линейна, веса подбираются решением задачи на минимизацию дисперсии оценки, а внутренняя несмещенность обеспечивается применением множителя Лагранжа, задающего равенство суммы весов единице, а также "универсальный” кригинг [Deutch & Journel, 1992], во многом подобный предыдущему, но со вводом в систему уравнений модели локального тренда и использованием остаточной вариограммы (в последнем случае имеются небольшие технические сложности: так как тренд моделируется без нормализации, в каждой точке приходится отдельно решать систему уравнений тренда, после чего вычленять остатки и решать систему вторично). Казалось бы, очевидно, что имея дело с линейными весовыми функциями и арифметическими средними, мы гарантируем итоговую несмещенность, но в реальности имеет место еще один, и очень важный, фактор. Веса рассчитываются без учета значений в пробах, только по их геометрии, а значения, точнее, всевозможные характеристики их пространственной взаимосвязи, используются только для выбора формулы или алгоритма расчета весов. Именно отсюда и следует равенство математических ожиданий исходной и смоделированной переменной. Очевидно также, что при невыполнении любого из этих трех требований мы такую гарантию теряем. Уточним, что теряем не собственно несмещенность, а именно ее гарантию. То есть, любой хороший алгоритм интерполяции или оценивания в корректной ситуации обеспечивает доказуемую несмещенность, но в некорректной ситуации алгоритм, не обеспечивающий трех вышеуказанных условий, эту доказуемость теряет. Тем самым, к примеру, обычный и универсальный кригинг, наряду со статистическими методами, гармоническими функциями гарантирует при данном подходе несмещенность, а "ускоренный" кригинг сводящий системы уравнений к специальному виду, позволяющему на порядок повысить скорость обработки) или дизъюнктивный кригинг - нет [Аронов, 1990; David, 1988; Reply, 1981]. Не обеспечивает несмещенности также любая процедура с ограничением "ураганных значений", реализуемом не на исходных данных, а в процессе построения весовых функций. Остановимся также на наиболее опасной из распространенных ситуаций. Авторам неоднократно приходилось встречаться с тем, что для целей оконтуривания в массив исходных проб вносятся законтурные реальные или фиктивные пробы с нулевыми значениями. При логарифмировании они большинством программ автоматически удаляются, и тем самым вычисление арифметического среднего исходных данных и арифметического среднего логарифмов производится не по одной и той же выборке, что вносит существенные искажения, к тому же систематические. Для сохранения свойств подхода следует при вычислении среднего нелогарифмированных данных в обязательном порядке удалить нулевые пробы. Вопрос с блочными оценками не столь прост. При получении блочной оценки есть две фазы - построение множества точек внутри блока и построение весовой функции на блок в целом. Поэтому смещение оценок при нелинейных трансформациях возникает “с двух сторон”, и компенсация должна вводиться не после отработки алгоритма получения оценки, а внутри него. У автора пока нет готовой реализации такого алгоритма, но теоретические сложности здесь минимальны. Выводы Весьма важным представляется то, что подкласс распределений Кептейна, поддающихся предлагаемой схеме компенсации смещения оценок, достаточно широк, чтобы с удовлетворительным качеством описать практически любые реальные распределения. Универсальность компенсирующего множителя в пределах этого подкласса означает потенциальную возможность автоматизированного выбора из этого подкласса нормализующего преобразования с полным отсутствием проблемы корректного несмещенного возврата к исходному масштабу данных [Мальцев, 1994]. Естественно, некоторый период логического осмысления этой концепции на предмет ее уточнений и поисков возможных ее противоречий геологическим соображениям необходим, но, во всяком случае, путь открыт. Литература 1. С.А Айвазян, И.С.Енюков, Л.Д.Мешалкин. Прикладная статистика. Основы моделирования и первичная обработка данных. -М.:Финансы и статистика. - 1983. -471с. 2. В.И.Аронов. Методы построения карт геолого-геофизических признаков и геомеризации залежей нефти и газа на ЭВМ. -М.:Недра -1990 -301с. 3. В.А.Мальцев. О некоторых свойствах линейного крайгинга. В кн:Практическая геостатистика. Труды всесоюзного семинара. КНЦ АН СССР. -1991. -с. 24-41. 4. В.А.Мальцев. Практическое руководство по применению геостатистических методов оценки в геологии (на базе программной системы GST)/Всесоюзный научно-исследовательский институт минерального сырья (ВИМС). -М.:ВИЭМС.-МГП "Геоинформмарк". -1991. -109с. 5. В.А.Мальцев. Программный комплекс геостатистического моделирования и оценивания GST 3.02 - учебник и руководство пользователя. -М.:В.А.Мальцев. -1993. - 153с. 6. В.А.Мальцев. Геостатистический подход к подсчету запасов. Разведка и охрана недр, N11, 1993, с. 8-11. 7. В.А.Мальцев. Методы создания программных средств управляемой интерполяции в геологических задачах. Руды и металлы, N1, 1994, с. 79-89. 8. Справочник по теории вероятностей и математической статистике. Под ред. В.С.Королюка. -Киев:Наукова Думка. -1978. -582с. 9. David M., 1988, Handbook of Applied Advanced Geostatistical Ore Reserve Estimation. Elsevier scientific publishing company, Amsterdam, 216p. 10. C.V.Deutch, A.G.Journel, 1992. GSLIB: geostatistical software library and user’s guide. Oxford University Press, 340p. 11. R.J.Howarth, S.A.M. Earle, 1979. Application of a generalized power transformation to geochemical data. Math. Geol., Vol. 11. No. 1, p. 45-60. 12. A.Journel, 1980. The lognormal approach to predicting local distributions of selective mining units grades. Math. Geol., Vol. 12, No. 4, p. 285-303. 13. Reply G. D., 1981, Spatial Statistics. John Wiley and Sons, New York, 252 p. 14. G.Verly, 1984. Estimation of spatial point and block distributions: the multi-gaussian model. PhD Thesis, Stanford University, Stanford, CA. 
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
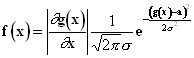 .
.